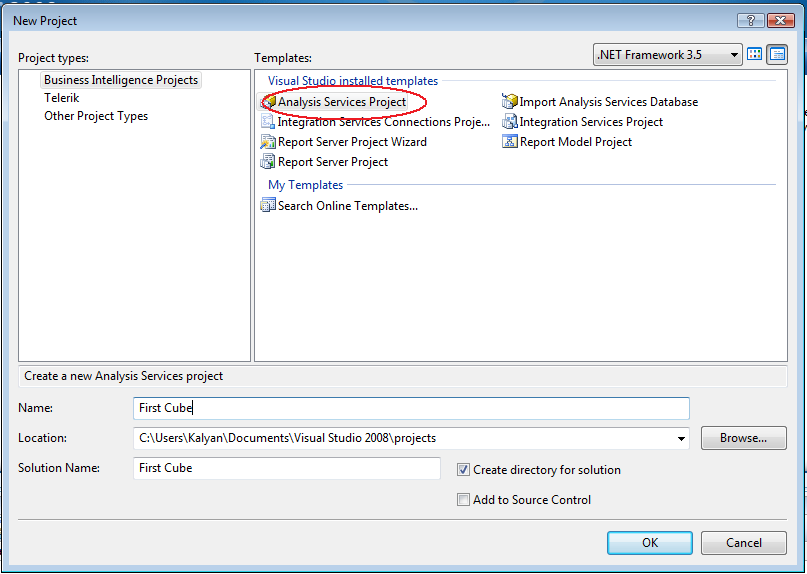
To create a cube, we need to create a Analysis Services Project in
Visual Studio. Start Visual Studio, select File, and New Project. In project
dialogue box, select Business Intelligence Projects from Project Types and
select Analysis Services Project from right in the dialogue box.
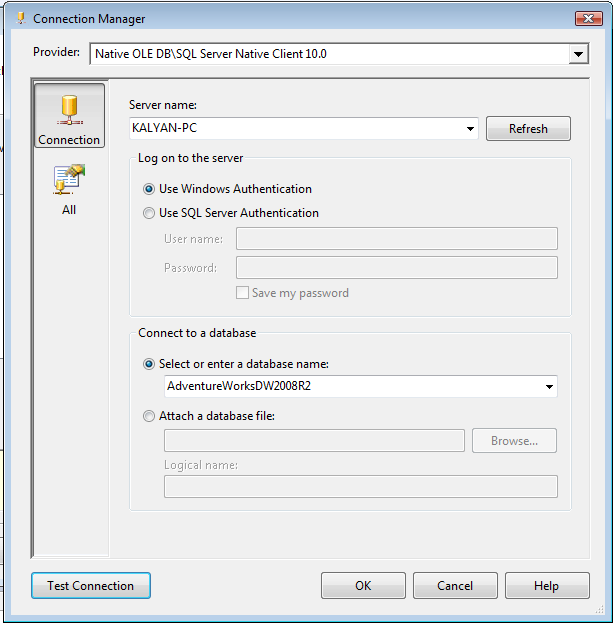
1. To represent a
connection to a cube, create a new Data Source for CUBE as shown in the below
dialogue


2. Adding a Data Source View to CUBE
After creating a database
connection to the CUBE, we need to specify what objects needs to be participate
in CUBE building. To do this we need to add a new Data Source View, we
can add DSV to project by right clicking on Data Source Views Folder in
solution explorer and say New Data Source View from options
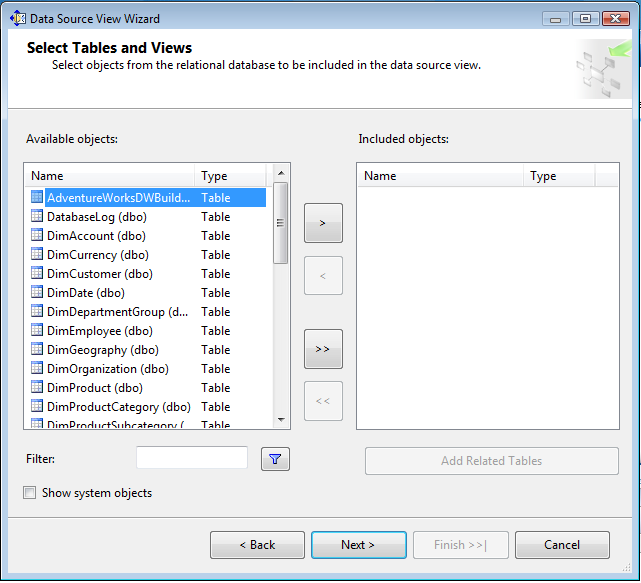
Select the relevant FACT and
Dimension tables from above dialogue. When you are not sure about what table
needs to be selected from CUBE building then select FACT table and say Add
Related Tables.

Once you finish the steps
in above dialogue then you will be seeing the following screen in Data Source
View Editor
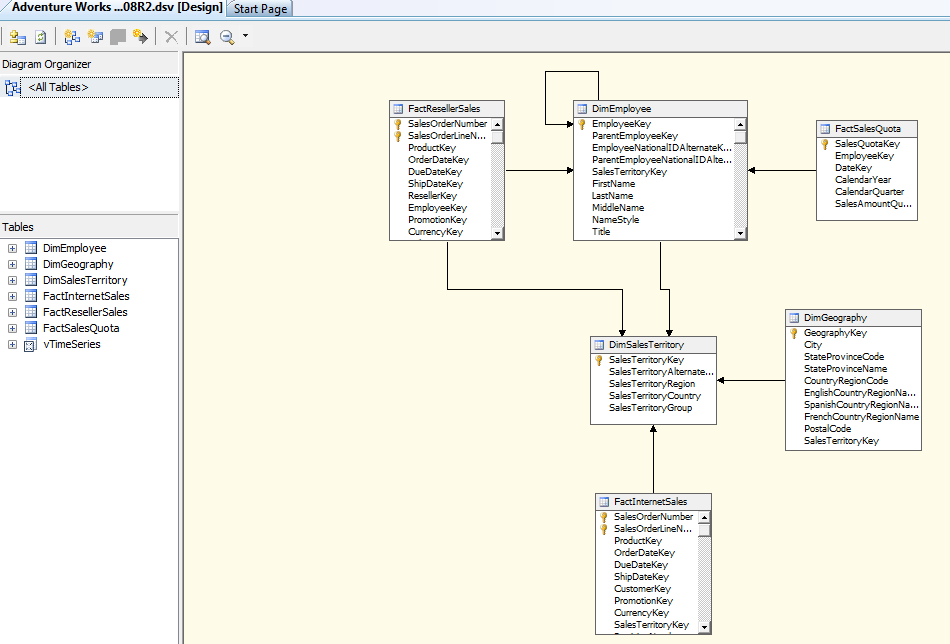
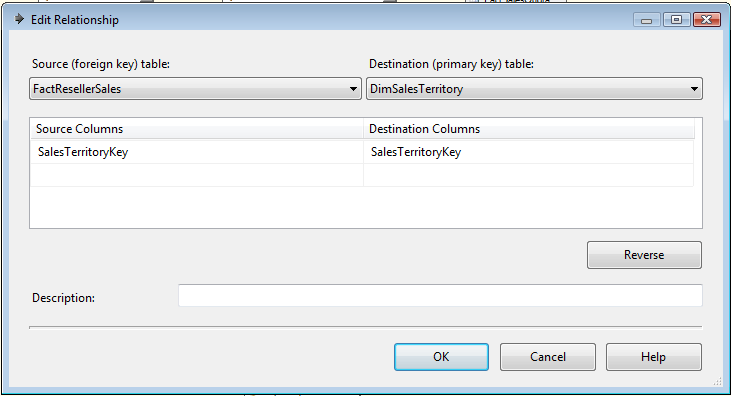
By default, all
foreign key constraints are added between the tables as shown in the above
diagram. You can edit or create the relationship by right clicking on the
design area
3. Creating a CUBE with CUBE wizard
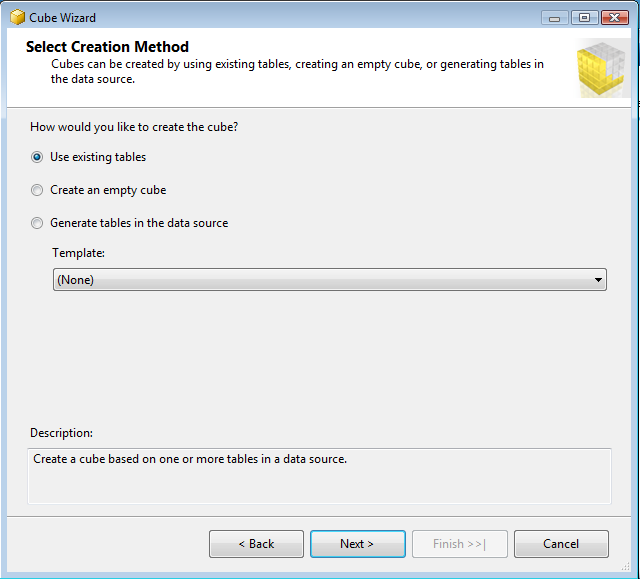
Once we have finished
creating a Data Source View then you are ready to build the CUBE . To do this we
can right click on CUBES folder and then click on New CUBE then you will be
seeing the following dialogue after clicking next
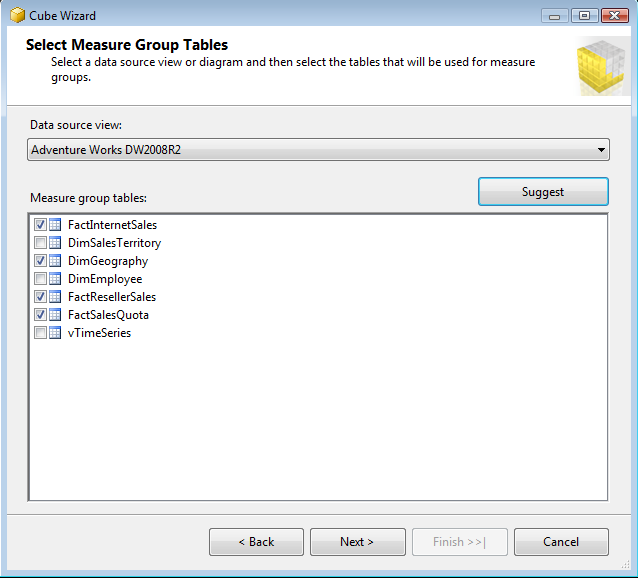
Click Next from the above
dialogue then select the Data Source View from down and then select the objects
that needs to be participate in CUBE development. If you are not sure then
click on the suggest button
Click next and select the
desire measure columns and dimensions from the Data Source View finally we will
see the following screen in finishing step

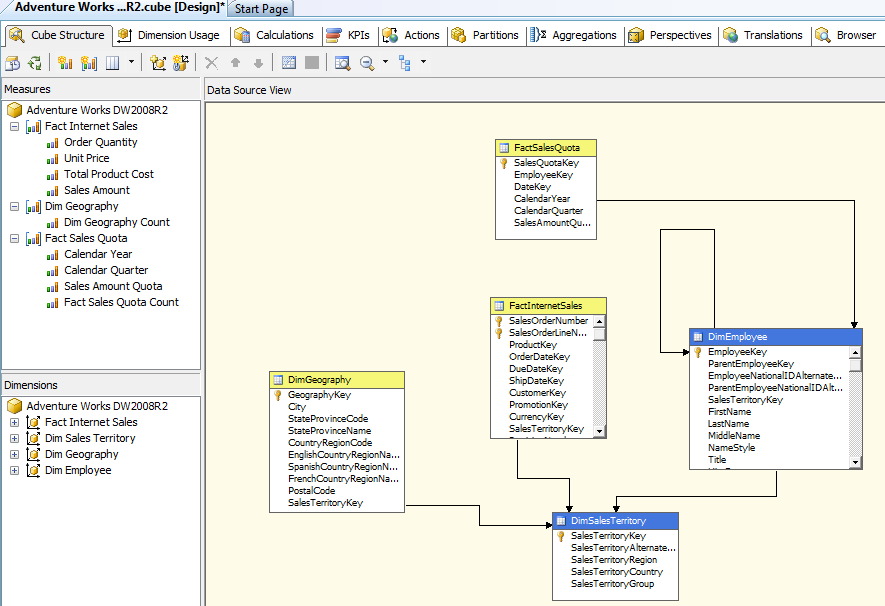
Once you hit the finish
button then you will be placed in the following screen
4. Browsing the created
CUBE
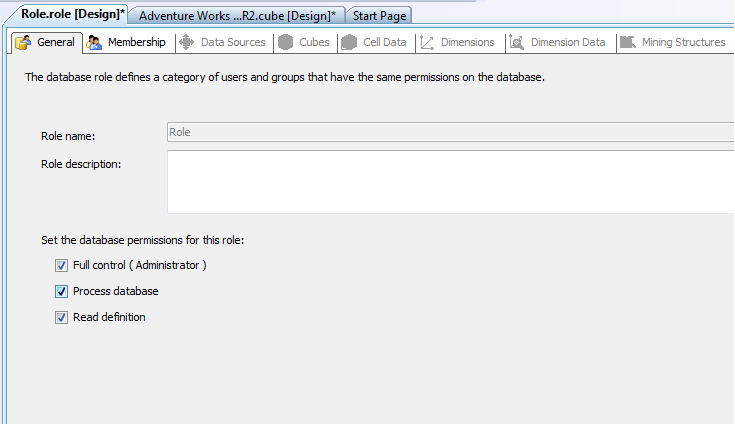
To access the above created
CUBE, you need to add a role and add the user to that role created.
5. Process the CUBE after
deploying it to the server
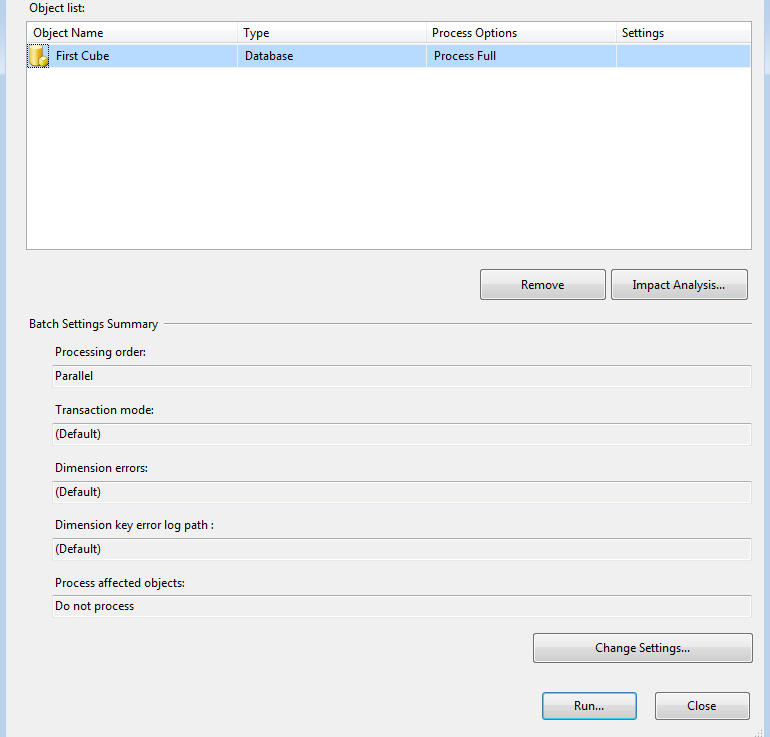
Processing your CUBE
requires that your analysis services project be built and deployed. You can
watch the progress of the build and deploy operations in deployment progress
window. Once the processing of CUBE has completed then your CUBE should be
ready for querying! In next post I will show how to query the CUBE using
CUBE browser wizard.
CubeThe basic unit of storage and analysis in Analysis Services is the cube. A cube is a collection of data that's been aggregated to allow queries to return data quickly. For example, a cube of order data might be aggregated by time period and by title, making the cube fast when you ask questions concerning orders by week or orders by title.
Cubes are ordered into dimensions and measures. The data for a cube comes from a set of staging tables, sometimes called a star-schema database. Dimensions in the cube come from dimension tables in the staging database, while measures come from fact tables in the staging database.
Dimension table
A dimension table lives in the staging database and contains data that you'd like to use to group the values you are summarizing. Dimension tables contain a primary key and any other attributes that describe the entities stored in the table. Examples would be a Customers table that contains city, state and postal code information to be able to analyze sales geographically, or a Products table that contains categories and product lines to break down sales figures.
Dimension
Each cube has one or more dimensions, each based on one or more dimension tables. A dimension represents a category for analyzing business data: time or category in the examples above. Typically, a dimension has a natural hierarchy so that lower results can be "rolled up" into higher results. For example, in a geographical level you might have city totals aggregated into state totals, or state totals into country totals.
Hierarchy
A hierarchy can be best visualized as a node tree. A company's organizational chart is an example of a hierarchy. Each dimension can contain multiple hierarchies; some of them are natural hierarchies (the parent-child relationship between attribute values occur naturally in the data), others are navigational hierarchies (the parent-child relationship is established by developers.)
Level
Each layer in a hierarchy is called a level. For example, you can speak of a week level or a month level in a fiscal time hierarchy, and a city level or a country level in a geography hierarchy.
Fact table
A fact table lives in the staging database and contains the basic information that you wish to summarize. This might be order detail information, payroll records, drug effectiveness information, or anything else that's amenable to summing and averaging. Any table that you've used with a Sum or Avg function in a totals query is a good bet to be a fact table. The fact tables contain fields for the individual facts as well as foreign key fields relating the facts to the dimension tables.
Measure
Every cube will contain one or more measures, each based on a column in a fact table that you';d like to analyze. In the cube of book order information, for example, the measures would be things such as unit sales and profit.
Schema
Fact tables and dimension tables are related, which is hardly surprising, given that you use the dimension tables to group information from the fact table. The relations within a cube form a schema. There are two basic OLAP schemas: star and snowflake. In a star schema, every dimension table is related directly to the fact table. In a snowflake schema, some dimension tables are related indirectly to the fact table. For example, if your cube includes OrderDetails as a fact table, with Customers and Orders as dimension tables, and Customers is related to Orders, which in turn is related to OrderDetails, then you're dealing with a snowflake schema.

No comments:
Post a Comment